Building Cognitive Machines
By: Mike GashlerLet's survey some thoughts and ideas about building cognitive machines.
What is a cognitive machine?
Cognition refers to the thinking processes that humans perform as they acquire knowledge and reason about their choices. A cognitive machine, therefore, is a machine capable of similar types of thinking.
This article will not attempt to resolve any hot button topics, such as sentience, or determinism vs. free will. I'm not trying to build a full artificial human--at least not yet. I just want to discuss some of the major components of cognition that I observe in how humans learn and make decisions.
Hierarchical design
Life is clearly hierarchical in nature. Organelles work together to form a cell. Cells work together to form organs, and organs work together to make a whole person. Humans work together to form families. Families make up communities, which make up nations, which make the global society.
The same systems that can be seen in individuals also appear in societies. For example, highways, roads, and delivery vehicles perform a job very much like a circulatory system, delivering nutrients throughout the body. Police officers perform a job very much like an immune system, controlling infections and misbehaving cells. National borders and border patrol agents perform a job similar to the integumentary (skin) system, keeping out unwanted external pathogens. Governments perform a role similar to the endocrine system, regulating metabolism, growth and development, and tissue function. The Internet performs a role very similar to a nervous system, rapidly sending messages throughout the body. And power generators perform a role very similar to the respiratory system, reacting oxygen with fuel to produce energy. Even our attempts at space exploration have much in common with a reproductive system that has not yet fully matured. These analogies exist precisely because life follows patterns, and those patterns are hierarchically self-similar.

Figure 1: Hierarchical self-similarity in the Mandelbrot set.
Thus, one significant goal in the design of cognitive architectures is for it to have the capability to specialize and stack in such a manner that many intelligent agents can each perform specific roles, and together form an aggregate intelligence greater than any of the individuals. In many ways, this suggests that understanding cognition is a lot more than a curiosity for enthusiasts of artificial intelligence. In the process of solving individual cognition, we may at the same time learn the principles that give cells life, the principles that make an economy thrive, or the principles that are most effective for governing a nation. Thus, understanding general cognition might be the grand problem that unites everything.
...or maybe not. Maybe the only effective way to implement cognition is unique for every application. Maybe the challenges get harder at every level in the hierarchy of life. But if that is the case, it would certainly be helpful to have the assistance of cognitive machines to help us start working on the harder problems at the next level, wouldn't it?
One pattern we can observe in the hierarchies of intelligent life is that there tends to be more communication within intelligent units than there is between them. For example, each of the approximately 80 billion neurons in a human cerebrum is directly connected to an average of about 10,000 other neurons. By contrast, each of the approximately 8 billion humans on Earth has a social network with an average connectivity at most in the hundreds. Moreover, communication between humans requires messages to be encoded into language, which significantly encumbers the bandwidth of communication.
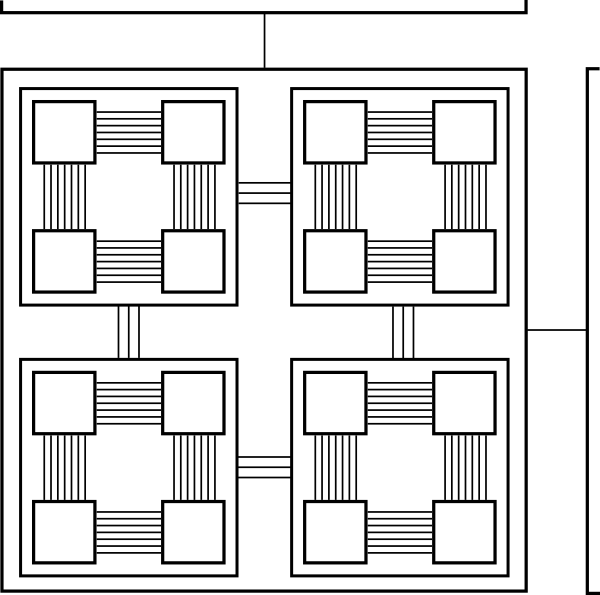
Figure 2: There seem to be more connections within hierarchical units of cognition than between them.
Is this a really beneficial principle, or just a practical necessity? I don't know for sure. But the relatively limited bandwidth between units seems to have at least one beneficial effect: It causes each unit to go to the effort to produce meaningful packets of information when it communicates. Many linguists have hypothesized that language has been a driving force behind the development of human cognition. Perhaps a piece of the puzzle to cognition may be found by studying linguistics or humanities. Perhaps other pieces may be discovered within the principles of economics or politics. I think trying to solve this problem while considering only the field of artificial intelligence is likely to produce an effective agent that cannot think effectively under novel conditions. And that is the opposite of cognition.
Separation of learning and planning
Let us consider three instances in which cognition has evolved: 1. In the early years of artificial intelligence, many different reflex agents were implemented. A reflex agent is an agent that uses hard-coded logic to choose its actions as a direct function of its percepts. 2. In the early years of human society, superstitions played a central role in helping people determine what choices to make, without fully understanding how things really worked. 3. In the early years of biological evolution, primitive animals developed simple nervous systems that responded reflexively to the stimulus they received.
As the field of artificial intelligence progressed, a new discipline called machine learning emerged. Machine learning builds models of data. The goal is for these models to accurately represent the environments that produced the data. These models gave artificial intelligence a huge boost because now agents could use the knowledge from machine learning models make more informed choices.
As society developed, a particularly significant event called the Renaissance occurred. The Renaissance refers to a time when people started trying to understand their world, rather than focus exclusively on making choices to maximize their personal well-being. As science surged ahead, people started to have a better foundation for the choices they made, and society as a whole began to function much more intelligently.
As biological creatures evolved, mammals began to emerge with large cerebrums. The cerebrum is the part of the brain that learns to model the environment, understands the meaning encoded within our percepts, and produces awareness. It is what makes us distinctly conscious, in contrast with relatively reflexive simple creatures.
A very clear pattern can be seen in these three examples: Effective cognition emerges when a system begins trying to model and understand its environment, rather than merely respond reflexively to its immediate conditions.
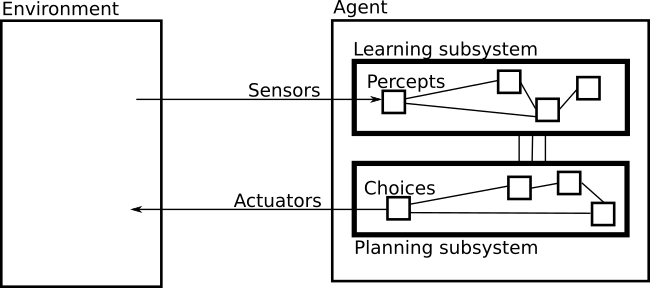
Figure 3: At the highest level, cognition naturally decomposes into learning and planning. The learning subsystem acquires knowledge to model the environment. The planning subsystem seeks to use its knowledge to make wise choices.
It follows that a cognitive system should include a significant subsystem dedicated to learning from its percepts. The goal of the learning subsystem is to produce accurate beliefs about the agent's environment, and the goal of the planning subsystem is to leverage those beliefs to make good choices. In other words, cognition can be reduced to the pursuit of two virtues: knowledge and wisdom. The learning subsystem remembers and looks into the past to seek true knowledge. And the planning subsystem forecasts into the future to make wise choices based on its knowledge.
Competitive learning
Since the learning and planning subsystems have different purposes, they also should learn from different (and perhaps even opposing) error signals. The planning system's job is to help the agent obtain desirable results, so it is most effective when the actual consequences of an agent's choices match what was expected. However, that is not necessarily what is best for the learning system.
In general, the greatest amount of learning occurs when something unexpected happens. However "unexpected" means something different to the learning subsystem than it does to the planning subsystem. The learning subsystem should be surprised when it fails to forecast the consequences of an action. (Consequences are a matter of fact, so they fall under the purview of the learning subsystem.) By contrast, the planning subsystem should be surprised when its own well-being is affected differently than it anticipated. (Priorities are a matter of subjective value, so they fall under the purview of the planning subsystem.) So to benefit the planning system, an agent should habitually gravitate toward places in the environment where it already understands the consequences of its actions, so it can work on refining its priorities. And to benefit the learning system, it should curiously explore the mysterious regions of its environment where its model fails to predict the dynamics. The moral is, you cannot use the same error signal to train both subsystems, or else the agent will do its best to avoid training one of them.

Figure 4: The planning subsystem builds on top of the learning subsystem, but that does not imply errors backpropagated from the planning subsystem will necessarily improve the learning subsystem.
Since the planning subsystem uses the models produced by the learning subsystem to do its job, it might be tempting to suppose that both models can be trained by backpropagating the same error signal across both components. But this is a place where caution may be important. The learning system should never be encouraged to bend what it believes to be true in order to make the planning system more content with its outcomes.
When humans give preference to beliefs that tell them what they want, we call this confirmation bias. When confirmation bias is involved, humans have a tendency to "know" some rather absurd things. That's not what you want to happen to your learning subsystem. The cure for confirmation bias is to keep learning system in the dark about what the agent wants to be true.
And likewise, the agent should not be rewarded for going in circles to ensure that its learning system can easily forecast the dynamics of the environment. Thus, these two major components should probably be designed to learn in a competitive rather than cooperative manner.
Why are cheetahs so fast? Because antelopes are fast. A slow cheetah is a hungry cheetah. Why are antelopes so fast? Because cheetahs are fast. A slow antelope is the cheetah's meal.
Transductive learning
The two dominant methods of learning are unsupervised learning and supervised learning. (We'll discuss some other types of learning later.) If you are interested in building a cognitive architecture, you are probably already intimately familiar with these two types of learning. (If not, you should definitely spend some time studying those topics before proceeding.) Figure 5 offers an illustration of the basic difference between these two types of learning.

Figure 5: Both unsupervised and supervised learning are essential for understanding this picture. Unsupervised learning enables an agent to simplify and understand things. For example, this picture contains six animals. One of them is significantly different from the others. Supervised learning enables an agent to associate things. For example, the animals in this picture are called "owls" and "cat". Also, one would expect the owls to say "hoohooo", and the cat to say "meow".
Unfortunately, a lot of modern architectures tend to emphasize supervised learning, and largely ignore unsupervised learning. This is understandable, since supervised learning is significantly more mature, but I am of the opinion that ignoring unsupervised learning is a big mistake. From a practical perspective, the amount of unlabeled data available almost always far exceeds the amount of labeled data. I believe the vast majority of the learning that humans do is unsupervised, and only a small amount of it is augmented with supervised learning. From a biological perspective, we can observe that the cerebrum covers a large portion of the brain (literally), and plays a huge role in human cognition. (The cerebrum is the part of the brain the does unsupervised learning.)
Perhaps the best way to figure out how unsupervised learning and supervised learning can work together in a learning system is to study transductive learning. Transductive methods are somewhat lesser-known. They combine both supervised and unsupervised techniques into a system that can learn more generally from data. Figure 6 illustrates how transductive methods make use of more data for learning than either supervised or unsupervised learning alone. In my opinion, some form of transduction is needed in the learning component of an effective cognitive architecture.
Figure 6: Supervised methods learn from the training features and training labels. Unsupervised methods learn from the training features and test features. Transductive methods combine both approaches to learn from all three components of data. (No, you can't also learn from the testing labels. Predicting those is the objective, so including those in the learning process is called "cheating".)
I'm not going to go into the details of transductive learning in this article, so if you're not already familiar with it then that's something to add to your list of topics to study.
Modality fusion
I can recognize my wife by her appearance. If the lights are out and she speaks, I know her voice as well. And if I touch her, I expect to feel a familiar warmth and softness. Yet in my head, all of these sensations translate to an awareness of her presence. This ability is called modality fusion. Each type of data that I can sense is called a modality. And fusion is combining information from these senses into a unified representation of what I believe is the current state of my world.
Even with my eyes closed, I can reconstruct an image of my wife by imagining how she looks. I can similarly imagine her voice, her smell, or the way she feels. And my fantasies need not be static. I can anticipate what might happen next. I can begin playing the scene forward in my mind, producing an imaginary scenario. And as this imaginary scene plays out, I can imagine audio, visual, olfactory, and other sensations that correspond with the state at each time-step.
How can we give a cognitive architecture the same ability to operate with a diversity of senses in a temporal environment? Figure 7 shows a candidate design that could theoretically do this.
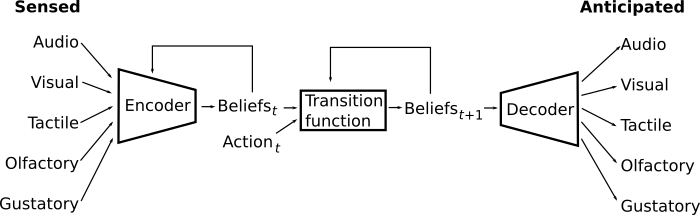
Figure 7: Humans combine data from multiple different senses into a unified representation of beliefs about the state of their world. Beliefs are only updated by each observation, so the previous beliefs also influence the output of the encoder. A transition function anticipates future states. Beliefs can be fed through the transition function any number of times to project arbitrarily far into the future. And at each anticipated time step, the agent can anticipate future observations or sensations.
There is no rule that says a big complex system must be trained with all of its components hooked together in the way they will be used. In this case, it will be much easier to train the encoder and decoder without the superfluous complexities of time or state transitions. So, each time an observation is made, these two components could be trained as a simple autoencoder, as in Figure 8.
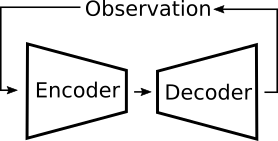
Figure 8: The encoder and decoder components do not need to be aware of state transitions while they are being trained. But they can still be used in the presence of state transitions, as in Figure 7.
Similarly, the transition function would be much easier to train in a simple supervised manner. The encoder can be used to obtain estimates of beliefs, both before and after state transitions. Then, these beliefs can be applied to train the transition function in a simple supervised manner, as in Figure 9.
Figure 9: The transition function can also be trained in isolation from the other components. All that is required is some way to compute beliefs, and the autoencoder provides that functionality.
It is not yet completely clear whether it is necessary, or even beneficial, to consider the recurrent connections when training the transition function. It is also not yet clear how exactly to train an encoder so that observations only refine beliefs, rather than recompute them anew. Hopefully, ongoing experiments will begin to find effective ways to make this happen. (In my opinion, this may be the biggest open challenge in building an effective cognitive architecture. Once we find a robust method for learning, I think most of the other major components of cognition will become much easier to implement, and will begin to naturally fall into place.)
Attention
Even though humans have many beliefs, they also seem to have the useful ability of identifying the relevant ones while remaining mostly undistracted by their many irrelevant beliefs. For example, imagine that you are standing in front of the Mona Lisa. If you imagine looking in the upper-left region of your visual field, you might expect to see something like the left image in Figure 10. And if you looked in the lower-right region of your visual field, you might expect to see something more like the right image in Figure 10.

Figure 10: Left: An upper-left region of the Mona Lisa. Right: A lower-right region of the Mona Lisa.
In this example, you probably didn't imagine that whole Mona Lisa painting somehow ceased to exist as a complete whole from the Louvre Museum in Paris. You were simply able to determine which portions of your beliefs about the appearance of this painting were relevant to the situation. Moreover, the price of tea in China probably didn't occupy much of your focus during that exercise, even though you are likely aware that tea can be purchased in China.
I think it is apparent that an agent that always considers everything it knows whenever it makes a decision must either be very slow, or cannot amass a large body of beliefs. Thus, the role of attention in cognition is probably to enable learning scalability. Figure 11 shows a basic diagram of an attention mechanism.
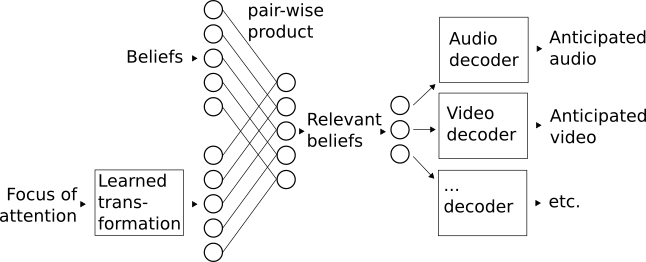
Figure 11: The role of an attention mechanism is to filter beliefs. In this example, "Focus of attention" specifies what the agent is currently thinking about. From this, a "learned transformation" computes a mask. This mask might contain "1"s to correspond with relevant parts of beliefs, and "0"s to correspond with irrelevant parts of beliefs. "Beliefs" is a dense vector specifying everything the agent knows. (In practice, a belief vector may be very large, but only 5 units are illustrated for practical reasons.) When this vector is multiplied by the mask, the resulting "Relevant beliefs" will be very sparse (mostly zeros). Since the relevant beliefs are sparse, the layer that follows can compress it to a very small number of values (indicated by the layer with only 3 units), and the decoder will anticipate observations that correspond with only the relevant portion of the agent's beliefs.
The crux of an attention mechanism involves performing a pair-wise product between beliefs and some mask. The mask is computed as a (learned) function of the representation of attention. That is, if the attention vector indicates that you are looking in the upper-left region of your visual field, then the mask could learn to represent 1's in the region that corresponds with that part of your beliefs, and 0's in regions that correspond with the parts of your beliefs you would not expect to see there. Then, the product of your beliefs and this mask produce a relevant set of beliefs that can be used to compute anticipated sensory information.
But how does the agent know where to focus its attention? In the case of a robot with a camera, the focus of attention would probably encode its location in the environment and the orientation of its camera (because that is what it would need to anticipate what the camera will observe). But what if the agent is contemplating something that it cannot directly observe? Does its focus of attention derive from a portion of its beliefs? Are they values it can control with its actions? Or are they imposed on the agent by the task it is currently seeking to achieve? While some success has been found with attention mechanisms, I believe the best way to use them in cognitive architectures still remains an open question.
If attention mechanisms are used in conjunction with the decoders, as suggested in Figure 11, another complexity is introduced into the system: This would make the decoders asymmetric with the encoders. That is, the decoders now anticipate only observations that correspond with "relevant beliefs". How can we similarly modify the encoders so they don't have to rely on the agent making unrealistically rich observations that contain enough information to specify everything the agent needs to know? Figure 7 suggested that this could be done with recurrent connections from the beliefs that feed back into the encoder. While that is one possibility, my own experimentation suggests that this approach may not really work very well.
Another potential solution is to eliminate the encoder altogether. Instead of using an encoder to recompute beliefs each time the agent makes observations, it is also possible to just refine the agent's beliefs as needed to enable the decoder to correctly anticipate the observations it makes. In other words, whenever the agent makes a new observation, the difference between actual values and the values it anticipated are computed. This difference serves as an error signal that can be backpropagated across the decoder and any prior attention mechanism to refine the agent's beliefs by gradient descent.
There are a few significant advantages of this particular design. Most obviously, getting rid of the encoder means there is one fewer component to train. Also, the agent no longer needs to learn how to preserve its beliefs over time. They are now preserved by default unless the agent changes them. This just seems more consistent with the way humans imagine their beliefs to persist. The agent no longer needs to make unrealistically rich observations that tell it everything it knows. And the attention mechanism naturally serves to ensure that only the relevant portion of beliefs will be updated when new observations are made. That is, the zeros in the "mask" will block the error signal from affecting portions of the agent's beliefs that are not relevant to the current observation.
Jeff Hawkins wrote a brilliant book called On Intelligence that explores in detail how the cerebrum anticipates observations and learns from how its expectations differ from what it actually observes. And if you are ready to learn more about attention, here is a a seminal paper that demonstrated how attention enabled researchers to top recurrent models and still achieve state-of-the-art accuracy at sequence-to-sequence translation. And here is a nice tutorial that presents this paper in a highly digested manner. Here is a paper that uses attention in a vision-based application. And here is two others.
A diversity of special-bias learning structures
Learning models with domain-specific structures often perform better for specific applications than general-purpose learning models. This paper showed that a big network with a diversity of special structures was able to learn to simultaneously handle multiple different problems. And significantly, the special-purpose structures even seemed to benefit the applications for which they were not designed. Thus, the intuition seems to be that the more weird stuff you cram into your learning models, the better they will probably do overall. I don't know just how far that principle should be pushed, but it's something to keep in mind as you design a cognitive architecture.
Regularizing
One principle that warrants mentioning is keeping the models simple. In the domain of learning, simplicity is captured by Occam's Razor, which suggests that superfluous complexity should be omitted from an explanation. In the domain of planning, simplicity is one of the chief characteristics that we recognize in wisdom. A saying with many nuances and subtle exceptions is never considered to be as wise as one that simply characterizes the right way to behave.
In learning models, regularization is the key to keeping a model simple. ElasticNet, which combines L1 and L2 regularization, is the time-honored standard for doing this. More recently, different versions of drop-out seem to be rising to dominate regularization approaches.
In planning systems, simplicity is implicitly promoted when a generalizing model is used to represent the Q-table. When q-values are updated in a generalizing model, this implicitly updates other regions of the policy space as well to follow similar patterns.
Learning priorities
At a high level, planning can be divided into two major components: (1) Some set of values or priorities, and (2) A mechanism that finds a sequence of choices anticipated to promote those values. Most advances in reinforcement learning have been made with the assumption that the environment provides a set of rewards or penalties to guide the agent. Essentially, this offloads the notion of forming priorities onto the environment. That is, someone has already reduced everything the agent should care about into a single-dimensional concept called "reward", and the agent's job is simply to maximize its long-term ("discounted horizon") reward. Of course, fully cognitive agents do not have the luxury of having their values just handed to them, so let's discuss what that might look like.
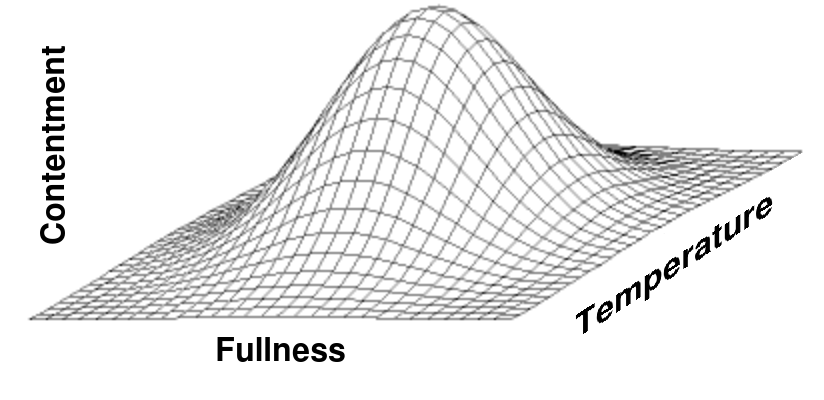
Figure 12: Humans are not content with temperatures that are too cold or too hot. Nor are the content when their stomach's are too empty or painfully over-full. Therefore a mapping from these two concepts to contentment would probably resemble some sort of hill-shape.
Humans balance a plethora of different priorities simultaneously. How do they know which of their many priorities deserve their attention at any given moment? A consistent utility function requires that their many priorities can all be reduced down to a single number, such that maximizing this number will represent the best balance over all the different factors. If extreme values are assumed to be undesirable, then a mapping from many different priorities to a single value would resemble some sort of hill-like structure, perhaps like the one depicted in Figure 12.
As time progresses, the environment tends to push the agent into regions of the space of lower contentment. (For example, imagine an agent tasked with keeping the lawn mowed but the grass just keeps growing, and with keeping the fence painted but the sun keeps shining on it.) In order to balance its priorities, all the agent really needs to do is seek the shortest path of actions that will return it to the top of the hill.
While humans probably model their priorities with similar shapes, there are also significant differences between them, as evidenced by the fact that people all make different choices. In my opinion, therefore, it is probably not very important to learn to model priorities with exactness. As long as the top of the hill is is approximately the right place, the agent will find a way to keep things in balance.
I can only think of two biologically-plausible ways that an agent might learn its model of priorities: (1) It could reverse-engineer a model of priorities by observing the choices of a teacher, or (2) Models of priorities could evolve within populations of agents over many generations of natural selection.
It's pretty clear that both of these mechanism happen in biology. Some of our priorities come pre-baked in our DNA. For example, hunger and general self-preservation are clearly part of being human. And it's also pretty clear that children who spend time with their parents often start to emulate their values.
If your goal is to produce an agent that operates completely on its own, independent of your own objectives, then this might be an important area to focus on. However, it is much more common to want to build a cognitive agent to pursue a specific objective dictated by its creator. Therefore, let's save this component as an area for research after we have demonstrated general cognitive abilities in other areas. In other words, maybe it is reasonable for now to just feed our agent hand-crafted rewards. After all, we don't really have to solve all of cognition in one shot, and it will save us from wasting a lot of time watching our agents pursue useless priorities as they slowly evolve better ones that we can agree with. So next, let's turn our attention to the second component of planning: a mechanism that searches for choices that maximize the agent's priorities.
Exploration versus exploitation
If you always eat at a random restaurant ("exploration"), the quality of your dining will be about average, by definition. If you always eat at your favorite restaurant ("exploitation"), you will never find a better restaurant. What a shame if you started exploiting after trying your first restaurant, For many years, epsilon-greedy was the standard method for balancing exploration with exploitation. It says that an agent should explore some relatively small (say 5%) portion of the time, and exploit some relatively large (say 95%) portion of the time.
More recently, curiosity has been recognized as an important factor in directing how an agent chooses to explore or exploit. The general idea is that the agent measures how accurate its forecasts are in different regions of its state space. When its forecasts are accurate, there is little reason to explore, so it mostly exploits. And where its forecasts are inaccurate, the agent feels drawn to explore those regions more thoroughly. Here's a video and a paper about curiosity-driven exploration.
In considering curiosity-driven exploration, remember that the agent needs to balance two competing types of learning: (1) Its learning subsystem needs to be able to accurately forecast the dynamics of its environment, and (2) its planning subsystem needs to be able to accurately forecast how rewards will be disseminated. Curiosity should be not be about encouraging just one or the other subsystem to learn well, but should seek some sort of balance to ensure that both subsystems learn to operate effectively. And since the agent can often maximize one system by sabotaging the other, I think it may be important to carefully ensure that the agent is incentivized to explore places that aggravate both aspects of its cognition.
Hierarchical planning
Deep Q-learning models provide a good starting point for building a planning system that seeks to maximize an arbitrary set of priorities. Deep Q-learning models consume state and produce Q-values for each action that the agent can perform in the state, as depicted in Figure 13.
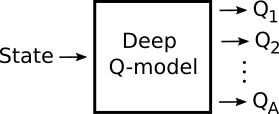
Figure 13: Deep q-learning models consume state and produce Q-values for each action.
When the agent is exploiting, it will perform the action that corresponds with the largest Q-value. And if the environment provides rewards, and the agent's objective is to maximize long-term discounted horizon rewards, then these models can be trained using Sutton's temporal difference method (based on the recursive Bellman equation). I will assume the reader is already familiar with deep Q-learning. If not, there are plenty of tutorials out there.
Two simple modifications make this model more suitable for a cognitive architecture. First, we can parameterize the actions by adding an additional input for actions and producing only a single Q-value. With this modification, we are no longer constrained to have a discrete set of possible actions. Now, the agent can sample from a continuous space of candidate actions, and choose the one that yields the largest Q-value. Second, instead of consuming "state", we will assume that the agent operates on its relevant beliefs instead. This means that the agent no longer has to have a perfect ability to observe the state of its environment. Figure 14 shows these adjustments.

Figure 14: A more robust model will operate on beliefs instead of state. Also, feeding actions as inputs enables the model to sample actions in continuous spaces.
Next, I think it is significant to recognize that humans plan in a hierarchical manner. As an example, let us consider a recipe for baking a cake. A good recipe is never linear. That is, a recipe for making a cake would never look like this:
- Start by making one quarter of a cake.
- Proceed until you have half of a cake.
- Continue until it is three-quarters done
- Finish by completing the whole cake.
Instructions like that would be completely useless! A useful recipe for making a cake would be more likely to contain instructions such as, "crack two eggs into a mixing bowl". Yet repeating this step many times would not bring the agent closer to having a completed cake. It would just result in a bowl with way too many eggs in it. Thus, making a cake is much more analogous with navigating a hyper-dimensional maze than it is with traveling in a straight line between two points in an empty hyper-dimensional space.
And how do we navigate such a complex hyper-dimensional maze? Sure we could, in theory, write a recipe that describes every step at an excruciating low level of detail. That is, it could tell you how to put one foot in front of the other to travel to the oven, how to coordinate your fingers to turn it on and start preheating, how to grip a stirring spoon, how to flex your arm muscles in order to create stirring motions, etc. But a recipe like that would not generalize well. If you tried it in some other kitchen, you might try to stir with a napkin, and the batter would probably end up on the floor instead of in the oven!
Clearly there is a significant advantages to describing actions in a hierarchical manner, where each major objective involves several sub-steps. Such instructions are more intuitive, and they can generalize by simply omitting the fine-grained details that differ from kitchen to kitchen. Figure 15 shows one possible way we could implement reinforcement learning so that it can learn to plan hierarchically.
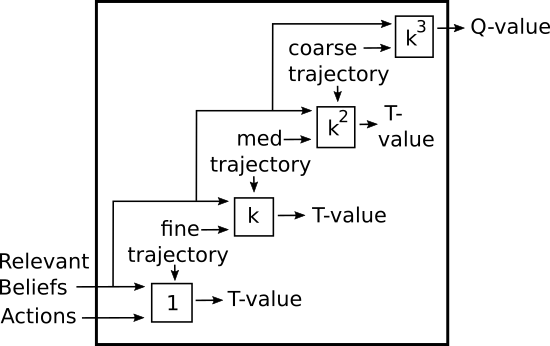
Figure 15: The Q-table can be implemented with a hierarchy of models to enable the agent to plan at multiple levels of granularity. When it is exploiting, the highest model in this hierarchy selects trajectories that maximize the Q-value. However, this model is updated at the lowest frequency. The more fine-grained models are both queried and updated more frequently. These models learn to choose actions or trajectories that are anticipated to lead toward completing the trajectory specified at the next higher level.
In this diagram, a trajectory refers to the difference between two belief vectors. At the finest level of granularity, a trajectory is essentially the same as an action, since it is just the difference between the current belief vector and the target one after one action. But at coarser levels of granularity, the two belief vectors are separated by more time-steps, so it represents a more high-level objective. For example, a high-level trajectory might be the difference between having raw ingredients and having a fully baked cake. So the finest-grained model will be used to choose "actions", and the more coarse models will choose objective milestones or "trajectories". A T-value is similar to a Q-value, except that a T-value refers to the value of performing a specified action or finer-level trajectory toward completing a coarser-level trajectory.
The first model in this proposed architecture (near the input end on the bottom-left) would operate at the most granular level of individual time-steps. It would feed into a model that chooses higher-level actions or "trajectories" spanning k time-steps. The model above it would choose yet higher level trajectories spanning k2 time-steps, and so forth until the highest-level model makes plans at the coarsest level of granularity. The coarsest model selects trajectories that are intended to maximize Q-values. The lower models in the hierarchy select trajectories that are intended to lead toward completing the trajectory that was selected at the next higher level. The lowest (most fine-grained) model in the hierarchy is updated after every time-step, like regular Q-learning. The next model above it is updated every k steps. And so forth.
Traditional Deep Q-learners use a "replay-buffer" that stores all of the recent choices the agent makes and the consequent value. In a hierarchical model, however, a replay-buffer would be needed at each hierarchical level. When the agent wishes to explore, random trajectories at any hierarchical level could be sampled by drawing from the replay-buffer, and jittering it with a small amount of Gaussian noise. And when the agent wishes to exploit, it could draw several random trajectories, and choose the one that yields the highest T-value.
To train an architecture like this, we also need a way to compute "rewards" for the models that predict T-values. For this purpose, let us define "contentment" as c=e-δ2/σ2, where δ is the distance that remains to reach the target trajectory, and σ is some deviation value, perhaps something like 0.2*δ0, where δ0 is the initial magnitude of the target trajectory. Then at each time-step, we can compute a reward as the difference in contentment before and after the step. Thus all the models in this hierarchical architecture can be trained with temporal difference learning. And each model should learn non-linear pathways to achieve the parent trajectory.
While it is learning, agents may sometimes seek to pursue impossible trajectories. That's not really a problem because the training process will update values for the trajectories that were actually achieved, not for the trajectories that were anticipated to be achieved. Thus, the agent will eventually learn which trajectories are possible for it to pursue, and its understanding of "value" will be distributed only along the pathways that are actually possible for it to follow.
Putting it all together and training it
So how does the learning subsystem fit together with the planning subsystem? I think this a really important question. If we can get this right, then I think the rest of the cognitive architecture will start to fall into place.
As I mentioned earlier, a planning system's goal is to maximize subjective priorities. By contrast, a learning system seeks to model the actual and measurable dynamics of an environment. As I consider Figure 15, I note that only the most high-level model in the hierarchy actually seeks to maximize subjective priorities. And all of the more granular models that compute T-values are actually modeling measurable dynamics, not subjective priorities. So even though this hierarchical model was originally intended to be a planning system, it looks like I may have inadvertently created both an architecture with both learning and planning components, as illustrated in Figure 16.
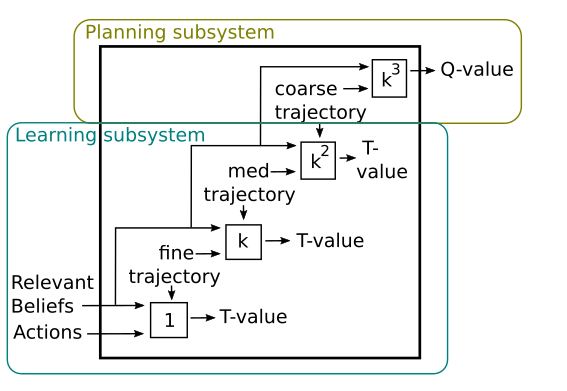
Figure 16: The highest level in the hierarchical planning system is the only component that seeks to maximize subjective priorities. The other components exist to learn to model the dynamics of the environment. This suggests that only the highest-level module is filling the role of a planning system, and the lower modules should actually be considered part of the learning system.
With that observation, it starts to become more clear how the other parts of the learning system fit into the overall architecture. Figure 17 shows a candidate architecture with all of the components we have discussed fitted together in a way that I think might actually work.

Figure 17: Here is one way that all of the components we have discussed seem to naturally fit together.
Note that there is only one decoder model. I see no need to train a separate decode at every level of the hierarchy, since beliefs for any time-step could be fed into it to obtain anticipated observations at that time. (This should not be interpreted as feeding all of the future beliefs into the decoder at the same time. It should be interpreted as any one of them being fed into the decoder to obtain anticipated observations for that time.)
Note that the relevant beliefs at time t feed directly into the decoder. Why would you want to predict observations at the present time-step when you could just directly observe them with the senses? Because the difference between the actual and predicted values is a valuable error signal for refining the beliefs. In fact, this is the primary mechanism by which beliefs are formed in this architecture. Most people would draw the arrows in the opposite direction, starting at observations and passing through an encoder to produce beliefs. However, I prefer to do it the other way, using backpropagation to refine beliefs, because this mechanism can work even when only partial observations are available, it eliminates the need for recurrent connections, and it makes the beliefs more persistent. If the agent is expected to make large context-shifting transitions, then it might be prudent to additionally add an encoder to this architecture that recomputes beliefs from observations.
Note that I added "T-value" as an additional output of the decoder. This might seem unnatural since T-values cannot be directly observed like the other modalities. But deep learning models generally do a great job of computing different types of outputs simultaneously, so I think this is a reasonable place to put them, even though T-values are still only computed internally.
Of course, there are still a few other necessary components that are not shown in this diagram. For example, some operations that are not shown include:
- compute Q-values from environmental rewards,
- compute T-values from internal contentment rewards,
- maintain and compute curiosity,
- choose actions for exploration and exploitation,
Conclusion
This is not the first cognitive architecture to be proposed. It will not be the last. And there is lots of work to do to bring it into being: Someone needs to implement it. Someone needs to develop a suite of tests for it. Someone needs to debug it against these tests. After that, someone needs to document the results and get them peer reviewed. Someone needs to do a survey contrasting it with existing cognitive architectures. Someone needs to identify its shortcomings with respect to other architectures. Someone needs to figure out how to improve it. Someone needs to use it to build an army of cognitive robots and take over the world! This is all going to be a lot of work. That's why I just wrote down my ideas for now. Wanna help?