Deep Q-learning
- (Optional) Please join our class forum. (If you joined before, you have since been booted, and must join again.) All subject lines from this forum will begin with "[ai]", so it will be easy to set up e-mail filters. I recommend using a pseudonymn instead of your real name. Anonymity helps some people feel more comfortable asking questions, and there is more anonymity if everyone does it.
- Visit the "View your scores" page and Change your password. (Initially, your password is the empty string. So, just leave the password blank.) If your name does not appear on the list, please e-mail the instructor. (Don't panic--this happens if you enroll after the instructor sets up this page.)
- Download this simple game:
- Java version (depends on JDK 7 or later)
- C++ version (depends on the packages g++, make, libSDL2-dev, and libsdl2-image-dev)
(I have only tested these on Linux, but I was careful to use only cross-platform components, so it should be relatively simple to port them to Mac or Windows. If you feel inclined to port it to yet another language, that would be nifty. Please share your improvements for the benefit of others.)
The objective of this game is to drive the cart in a way that keeps the pole upright. (I think this game is too difficult for humans to play effectively.) Take a little time to familiarize yourself with the code. - Read about Q-learning. Here is a reasonably simple tutorial about it.
If that one doesn't click for you, there are plenty of other good tutorials out there. I will also briefly cover Q-learning in class.
- Implement Q-learning.
Here is some pseudocode for one iteration of Q-learning.
(If you call this code a whole bunch of times under a variety of conditions,
the Q-table should eventually converge so that your agent makes intelligent choices.
A good place to put this code might be in Controller.update.)
// Pick an action Let Q be a table of q-values; // (we will use a neural network) Let i be the current state; // (get values from the model) Let ε = 0.05; // (this tells how frequently to explore) Let n be the number of possible actions; if(you are training and rand.nextDouble() < ε) { // Explore (pick a random action) action = rand.nextInt(n); } else { // Exploit (pick the best action) action = 0; for(int candidate = 0; candidate < n; candidate++) if(Q(i, candidate) > Q(i, action)) action = candidate; } // Do the chosen action do_action(action); // that is, apply the appropriate force and call Model.update() Let j be the new state // (new values from the model) // Learn from that experience Apply the equation below to update the Q-table. a = action. Q(i,a) refers to the Q-table entry for doing action "a" in state "i". Q(j,b) refers to the Q-table entry for doing action "b" in state "j". 1.0 might be a good value for αk when using a neural net for the Q-table. (Don't mix up "α" (alpha) with "a" (ay or eh?).) 0.97 might be a good value for γ (gamma). A(j) is the set of four possible actions. r(i,a,j) is the reward you obtained when you landed in state j. In this game, the objective is to keep the pole upright, so reward it accordingly. // Reset If the pendulum falls down, reset the game.Here is the equation that you will implement at the core of your Q-learner:
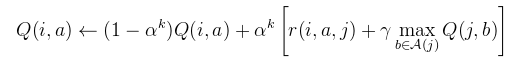
(I recommend reading all of the instructions before you start writing any code.) - Invent a reasonable representation of state. Write a function that maps from a Model object to a small vector that represents the current state. (In C++, use a Vec object. In Java, use an array of doubles.) Neural networks learn best when the input and target values fall approximately between -1 and 1, so I recommend normalizing values to fall approximately in that range.
- Implement the Q-table with a neural network.
Here is some code for a neural network:
- Java version (depends on JDK 7 or later)
- C++ version (depends on the packages g++ and make)
- forwardprop accepts one parameters: in. It computes a predicted output vector that corresponds with "in". (So, this is the method you will call to read from your neural network Q-table.)
- train_incremental accepts three parameters: in, target, and learning_rate. It modifies the neural network such that when you pass "in" to "forwardprop", the vector it computes will be a little bit closer to "target". (It doesn't update it all the way--just a little bit at a time--so it is necessary to call this method many times in a loop.)
- Implement a "replay buffer". That is, store any new "in" and "target" vectors in a big queue with some limited size. Whenenever you call "train_incremental", pick a random pair from this queue. This way, the neural network will not see too many training examples in the same region of its input space in a row. (Neural networks learn better when the training examples are presented in a random order.)
- Get it all working. Your cart should be able to balance the pole for about 5 seconds before it falls over.
I don't want to wait for your code to train, so please save your trained neural network model to a file,
and adjust your code to load this saved model.
When you run your program, it should immediately start balancing the pole.
Back up your code.
Delete all the generated binary files.
(I don't want to see any files with any of the following extensions: .exe, .suo, .sdf, .ipch, .ncb, .pdb, .o, .obj, .dll, .so.
In fact, I will configure my server to reject any submissions that contain files with those extensions.)
zip up your source code. Example:
zip -r -9 submission1.zip src
You can also use tarballs if you prefer. Do not use RAR. (That is a proprietary format, and I don't like proprietary formats when free formats are available. Why do people still uses RAR?) Make sure your archive contains a script named build.bash (or build.bat, if you use Windows) that builds your code. (It should not execute your code.) However, please have it print the command that I will need to enter to execute your code, so I don't have to figure that out. Make sure any filenames in your code use relative paths. (I do not have a folder named "C:\\Users\\Your Name\\Desktop\\School\\Artificial Intelligence\\Project 1" on my server, and even if I did, it would not contain the files that yours does.) Test your archive by unzipping it into another folder and running the build script. - Submit your archive by going to the main class page and clicking on "Submit a project". If you have any trouble with the submission server, don't panic, just e-mail your archive to the instructor.
Q and A:
(I will add more bullets here as students ask more questions.)
- C++ is confusing me. Can you help?
Here are some tips that students often find helpful with C++. In C++, be careful to only pass large objects by reference, not by value. If you forget the "&" when you declare function or method parameters, it will pass them by value. This may lead to double-free or memory corruption issues if the object you pass deletes memory in its destructor. - Why is "α" raised to the "k"th power?
It's not. "αk" does not mean "the learning rate raised to the kth power". It just means "the learning rate". The "k" is only there to let you know that it is okay to adjust the learning rate over time, if you want to. Although high school teachers have ubiquitously standardized on teaching that superscript always means "raised to the power of", scientists use that notation to mean whatever they want it to mean, so you have to read carefully to figure out what was actually intended. - How does one debug this complex system?
The key to debugging code is to understand what is happening, and contrast that with the expected behavior. How does one do that? Think of some questions you have about your code, then seek the answers. For example:
- Does your heuristic reward really reward good behavior more than bad behavior? (You might test this by printing the reward and temporarily slowing down the frame rate. Then, you can check to see if the reward is better when the pole is more vertical.)
- Is your Q-table changing over time? (You could test this by printing your Q-table at periodic intervals. Pipe the output to a file, then use a diff program to compare two parts of this output.)
- Is the agent deliberately choosing the majority of the actions that it actually performs? (You could test this by adding a counter to count the number of actions it chooses (in exploitation), and also counting the number of actions it actually performs (in Model.update). Then, compare these numbers. They should differ only by the exploration rate.)
- Are the Q values in good regions of the state space bigger than the Q values in bad regions of the state space? (They should be. You could test this by adding some code that waits until lots of training has occurred, then teleports to a good state and prints the Q values, then teleports to a bad state and prints the Q values.)
- Does your agent choose the best action when it decides to exploit? (You could test this by logging all of the numbers that pass through the exploitation code, then examining this log.)
- Are your action forces strong enough? (You could test this by temporarily making them stronger.) Are they too strong?
- Does your Q-learner work with simpler problems? (You could test this by implementing that 9-state grid-world game where the hero rescues the princess while avoiding the alligator pit, or some other simple game of your choosing.)
- Is your experience replay buffer working? (One way to test this is to stop using it. It should still work, but will take longer to converge. Another way is to write a little code to explicitly test it, outside of your regular program.)
- Does the neural net work? (You could test this by beefing up the demo test that came with the neural network.)
- Is the neural net clipping your values? (Add some code to throw an exception if your input or output values fall less than -1 or greater than 1. I strongly recommend adding as many self-debugging code-checks like this as you can think of. Don't worry about the cost in performance. Your time is worth way more than the computer's time.)
- Is the neural net the problem? (You could test this by temporarily replacing it with a regular Q-table. If that doesn't fix it, I recommend also trying a simpler problem and using a regular Q-table.)
- Does Math still work? Does my computer approximate Math correctly? Is there still determinism in this Universe? (If you are asking these questions, it is probably time to seek some assistance from someone who is not yet flustered.)
- Can you help me make a simple game that I can use to debug my code?
Sure. Here's one:
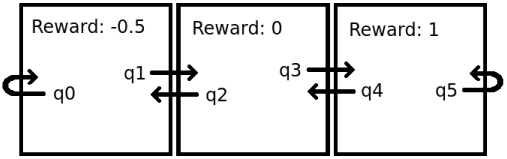
Now, let's manually derive what the q-values should converge to:
- q5 is the best option, so an intelligent agent should just sit there repeatedly choosing to follow q5, and obtain a reward of 1 each time. Therefore, q5 should converge to 1*γ0 + 1*γ1 + 1*γ2 + 1*γ3 + ... = 1 / (1 - γ).
- q4 should converge to 0 + γ * q3 (because this action gives a reward of 0, then the best path is to follow q3).
- q3 should converge to the same value as q5 (because it goes to the same state and obtains the same reward as q5).
- q2 should converge to -0.5 + γ * q1 (because this action gives a reward of -0.5, then the best path is to follow q1.)
- q1 should converge to the same value as q4 (because it goes to the same state and obtains the same reward as q4).
- q0 should converge to the same value as q2 (because it goes to the same state and obtains the same reward as q2).
So, if γ=0.6, then after an infinite amount of training, and if I did the math correctly, then
q0 = 0.4,
q1 = 1.5,
q2 = 0.4,
q3 = 2.5,
q4 = 1.5,
q5 = 2.5.